Ensuring data quality is an essential component of data engineering. Integrating Soda, a data quality monitoring tool, with Apache Airflow can assist automate and streamline the process. In this article, we’ll walk you through the process of integrating Soda with Airflow and using it to ensure high data quality standards in your pipelines.
Integrating Soda Data Quality Checker in Apache Airflow: A Step-by-Step Guide
Prerequisites
- Basic knowledge of
- Apache Airflow
- Apache Airflow installed and configured
- Soda SQL installed
- Access to a database (e.g., PostgreSQL,
- BigQuery, etc.)
Technology Used
Apache Airflow, BigQuery, SODA
Project Directory Structure
├──dags
| └──soda
| └──checks.yml
| └──configurations.yml
├──integrate_soda_with_airflow.py
Top level workflow
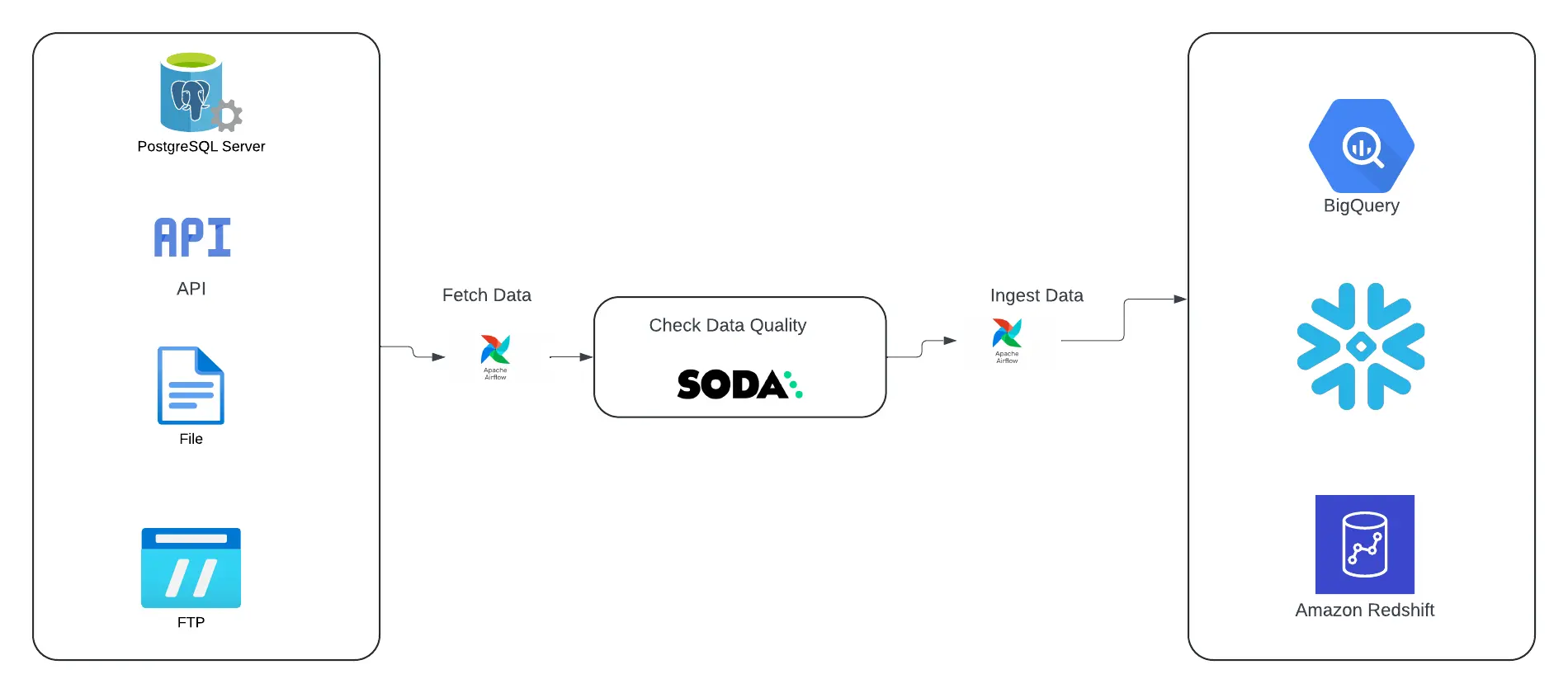
Fig 1: Integrate SODA with Airflow
Step 1: Install and configure Soda
Step 2: Create a Soda Scan DAG in Airflow
import os
from airflow import DAG
from datetime import datetime, timedelta
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.utils.edgemodifier import Label
from airflow.utils.task_group import TaskGroup
from soda.scan import Scan
from soda.common.yaml_helper import YamlHelper
default_args = {
'owner' : 'admin',
'retries': 2,
'retry_delay': timedelta(seconds=10)
}
soda_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'soda')
def _soda_check():
scan = Scan()
scan.set_verbose()
scan.add_configuration_yaml_file(os.path.join(soda_dir, 'configuration.yml'))
scan.set_data_source_name('my_bigquery_source')
scan.add_sodacl_yaml_files(os.path.join(soda_dir, 'checks.yml'))
scan.set_scan_definition_name('my_test_scan')
result = scan.execute()
print(f"result: {result}")
if result != 0:
print('Soda Scan failed')
else:
print("passed ... ")
with DAG(dag_id='DagDataQualityWithSODA'
, dag_display_name="validate the data quality with SODA ✅"
, default_args=default_args
, description='The pipeline will check and validate the data quality before and/or after data ingestion'
, start_date=datetime(2024, 8, 28)
, schedule_interval=None # manual trigger
, catchup=False):
# Tasks
# =======
# BashOperator
# ==============
with TaskGroup(group_id='fetch_data',
tooltip='fetch data from different sources') as fetch_data:
fetch_data_from_api = PythonOperator(task_id='fetch_data_from_api',
task_display_name ='🔗 Fetch data from API ',
python_callable=lambda: print("Fetch data from API"))
fetch_data_from_ftp = PythonOperator(task_id='fetch_data_from_ftp',
task_display_name ='📂 Fetch data from FTP',
python_callable=lambda: print("Fetch data from SFTP"))
fetch_data_from_postgres = PythonOperator(task_id='fetch_data_from_postgres',
task_display_name ='🐘 Fetch data from Postgres',
python_callable=lambda: print("Fetch data from Postgres"))
fetch_data_from_file = PythonOperator(task_id='fetch_data_from_file',
task_display_name ='📑 Fetch data from CSV/xls/xlsx',
python_callable=lambda: print("Fetch data from file"))
# taskgroup taskflow
[fetch_data_from_api, fetch_data_from_ftp, fetch_data_from_postgres, fetch_data_from_file]
soda_data_quality_check = PythonOperator(task_id='soda_check',
task_display_name='💯 Validate data quality before ingesting',
python_callable=_soda_check)
with TaskGroup(group_id='ingest_data',
tooltip='Ingest data into target databases') as ingest_data:
ingest_data_into_bq = PythonOperator(task_id='ingest_data_into_bq',
task_display_name ='🇬 ingest data into BigQuery',
python_callable=lambda: print("Fetch data from API"))
ingest_data_into_redshift = PythonOperator(task_id='ingest_data_into_redshift',
task_display_name ='🌐 ingest data into redshift',
python_callable=lambda: print("Fetch data from SFTP"))
ingest_data_into_snowflake = PythonOperator(task_id='ingest_data_into_snowflake',
task_display_name ='❄️ ingest data into snowflake',
python_callable=lambda: print("Fetch data from SFTP"))
# taskgroup taskflow
[ingest_data_into_bq, ingest_data_into_redshift, ingest_data_into_snowflake]
# task flow
fetch_data >> Label("fetch and validate data quality") >> soda_data_quality_check
soda_data_quality_check >> Label('Ingest data to target DB') >> ingest_data
Pipeline snapshot

Fig 2: SODA pipeline overview
Conclusion
Integrating Soda with Apache Airflow automates data quality tests, ensuring that your data pipelines are reliable and trustworthy. By following this guidance, you may implement automatic data quality checks in your own Airflow environment, delivering peace of mind while maintaining high data integrity standards.