
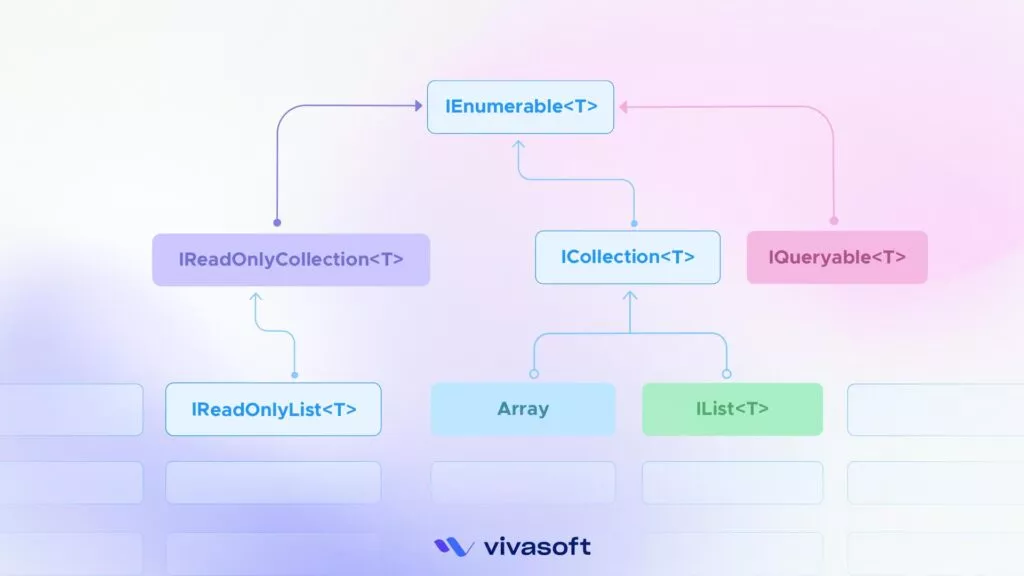
.NET provides a vast array of collection type interfaces built in. When choosing the right interface for a method, the basic principle is, choose the most generic interface as the arguments and the most specific for the return type. Have a look at the following diagram –

Given this hierarchy, which collection type should you use as a return value? Well, following the guideline, it should be the most specific type, but which one exactly? There are multiple leaves in this hierarchy tree:
Hierarchy Tree
IQueryable<T>
IList<T>
Array (such as int[])
IReadOnlyList<T>
Let’s discuss them one by one.
IQueryable
The first option is IQueryable<T>. an interface that facilitates database querying through LINQ expressions, like how one would interact with an in-memory collection:

The key distinction is that LINQ operations on IQueryable<T> are performed at the database level, rather than in-memory. ORMs like EF Core and NHibernate utilize an IQueryable<T> provider to convert LINQ expressions into SQL queries. Essentially, IQueryable<T> serves as an abstraction that enables uniform interaction with various data sources.
IQueryable<T> is particularly popular in repositories, where you can introduce a GetAll method, like this:
// Employee repository
public IQueryable<Employee> GetAll()
{
return _context.Set<Employee>();
}
And then use it to apply required filters in the controller:
// Employee controller
public IEnumerable<EmployeeDto> GetAll()
{
var employees = _repository.GetAll()
.Where(x => x.Email.EndsWith("@vivasoftemployee.com")); // Executed in the database
/* ... */
}
At first glance, this method appears rational. The client code, such as a controller in our scenario, can tailor IQueryable<T> filters according to specific needs. For example, as mentioned above, selecting employees with @vivasoftemployee.com emails. This filter is converted into SQL and executed within the database, thus preventing unnecessary data transfers between the database and our API.
However, returning IQueryable<T> has a considerable downside: it constitutes a leaky abstraction. As previously discussed, a leaky abstraction is one that inadvertently exposes the implementation details it is supposed to conceal.
When using IQueryable<T>, you must know which LINQ expressions can be converted into SQL and which can’t. Look at this code:
public IEnumerable<EmployeeDto> GetAll()
{
return _repository.GetAll()
.Where(x => x.Email.EndsWith("@vivasoftemployee.com")) // Can be translated into SQL
.ToList()
.Select(MapToDto); // Can't be translated into SQL
}
Here, the EndsWith method can be translated into SQL, but MapToDto cannot, which is why we initially invoke ToList(). This method instructs EF Core to execute the built-up query and load the resulting data into memory. Subsequent LINQ expressions are then executed against this in-memory data.
This situation exemplifies a leaky abstraction. When utilizing IQueryable<T>, it’s necessary to understand which LINQ expressions EF Core supports; not all LINQ expressions can be executed indiscriminately. In essence, one must be familiar with how EF Core implements its IQueryable<T> provider.
Don’t blame the tools! (EF Core and NHibernate) They try their best to translate as many LINQ expressions as possible into database queries. However, the underlying issue lies with the IQueryable<T> interface itself. It’s designed to be super flexible, allowing any LINQ expression, but that’s just not realistic. There are endless possibilities for LINQ expressions, but only a specific subset can be directly converted into queries understood by databases like SQL.
So, the problem is with expectations. Exposing methods that return IQueryable<T> might make it seem like you can use any LINQ operation on the data. But you’re limited by what the ORM can translate into database commands.
The same is true when you accept an expression as an argument in a repository, like this:
// Employee repository
public IQueryable<Employee> GetAll(Expression<Func<Employee, bool>> predicate)
{
return _context.Set<Employee>().Where(predicate);
}
Expressions, when used as part of the public API, are also leaky abstractions because they make it seem as though you can supply any LINQ expression to the method, whereas, once again, only a limited number of them can be understood by the ORM.
So, what’s the solution here?
Instead of exposing IQueryable<T> in the repository’s public API (which exposes internal details), you can return simpler data structures like collections or specific domain objects. Internally, the repository can leverage IQueryable<T> and LINQ expressions to efficiently manipulate the data using its knowledge of the specific ORM and its capabilities.
This way, clients of your repository wouldn’t need to worry about the underlying implementation details and wouldn’t be limited by the specifics of LINQ translation. They’d just interact with the data in a clean and straightforward manner.
Here’s how we can do this:
// Employee repository
public IEnumerable<Employee> GetAll(string emailDomain)
{
IQueryable<Employee> queryable = _context.Set<Employee>();
if (string.IsNullOrWhiteSpace(emailDomain) == false)
{
queryable = queryable.Where(x => x.Email.EndsWith(emailDomain));
}
return queryable.AsEnumerable();
}
Notice that the filter is now simplified to a basic emailDomain argument, ensuring that only filters supported by the ORM can be applied. Additionally, while IQueryable<T> is still used, it is confined to internal use within the repository and is not exposed externally.
The client code no longer needs to be aware of the internal workings of this method. Consequently, this method has evolved into a robust abstraction, in contrast to a leaky one.
IList<T>, Array and IReadOnlyList<T>
Don’t get confused with IList<T> and List<T>. The two are almost identical functionality-wise, and so even though technically, List is more concrete than IList<T>, in practice, it doesn’t really matter which one you use.
Can we use IList<T> or an array as the return value?
// Option 1
public IList<Employee> GetAll(string emailDomain)
// Option 2
public Employee[] GetAll(string emailDomain)
When choosing a return type, it’s crucial to avoid exposing unnecessary implementation details and to carefully select a type that accurately reflects the operations the client is permitted to perform on the returned data.
For example, the client code can change a list of an array of employees after it gets them from the repository:
IList<Employee> employees = _repository.GetAll("vivasoftemployee.com");
employees.Add(new Employee()); // We can extend the collection
employees[0] = null; // Or modify it
But what exactly means modifying that collection?
Typically, you might modify the collection for one of two reasons:
- You are adjusting the collection to add or remove employees from a database.
- You are repurposing the collection for a different task, such as filtering employees based on certain criteria, and instead of generating a new collection, you choose to modify the existing one.
However, both approaches are fundamentally flawed.
Returning a changeable collection might suggest that you can update the employees it contains just by adding or removing an item from the collection, but that’s not true.
Once the employee data is pulled from the database (right after the SELECT SQL statement runs), it’s no longer connected to the database. So, changing this data won’t affect the database at all.
Note: If you are using an ORM (like NHibernate or EF Core), then each employee in the collection is linked to the original data (rows in the database) and changing them will update the original data.
However, this isn’t true for the collection of employees itself. Changing this collection doesn’t add or remove data from the database
Because the data is detached, we shouldn’t use a changeable collection, as it doesn’t accurately show what the client can or can’t do with the database data. Also, you shouldn’t change the collection to use it for something else, like filtering. Unless there are serious performance issues (which is rare), you should make a new collection with filtered data instead.
Changing data when it’s not necessary can cause many hard-to-fix problems, which you can avoid by keeping the data immutable.
And so, we should only use immutable collection types for both arguments and return values.
Following the guideline, we should:
- Use
IEnumerable<T>for arguments as the most generic type possible. - Use
IReadOnlyList<T>for return values as the most specific type possible.
Here’s our GetAll method, refactored toward the use of IReadOnlyList<T>:
// Employee repository
public IReadOnlyList<Employee> GetAll(string emailDomain)
{
IQueryable<Employee> queryable = _context.Set<Employee>();
if (string.IsNullOrWhiteSpace(emailDomain) == false)
{
queryable = queryable.Where(x => x.Email.EndsWith(emailDomain));
}
return queryable.ToList();
}
We choose IReadOnlyList<T> over IEnumerable<T> because IReadOnlyList<T> offers more features straight away.
For example, it has a Count property and lets you access items by their index. IEnumerable<T> doesn’t have these features, and you often need to use LINQ extension methods to get similar functionality.
IReadOnlyList<T> isn’t always unchangeable behind the scenes. For instance, the List<T> class also implements IReadOnlyList, and in theory, you could convert IReadOnlyList<T> back to List<T> and change it.
However, doing this depends on how the IReadOnlyList<T> was originally created, which can make your code weak. The code that uses this should only depend on what the method signature shows and not assume anything beyond what the type of the object indicates. In simple words, avoid downcasting.
If you need to modify the returned collection, consider returning IList<T> instead of IReadOnlyList<T>, or create a new collection from the IReadOnlyList<T> you have.
IEnumerable<T>
IEnumerable<T> is also a leaky abstraction.
We should use IReadOnlyList<T> as the collection return type for the reasons mentioned. However, many well-known libraries, including parts of .NET’s Base Class Library (BCL), often use IEnumerable<T> instead, despite it providing less functionality compared to IReadOnlyList<T>. A key reason for this choice is the benefit of lazy evaluation.
In .NET, when working with IEnumerable<T>, most LINQ operations are evaluated lazily. This means that the computation on the data isn’t performed until you iterate over the items. This lazy evaluation can be very efficient for processing sequences where you might not need all the data or where the data set is very large.
Consider this example to see how lazy evaluation works with IEnumerable<T>:
int[] numbers = new int[] { 1, 2, 3 };
IEnumerable<int> r1 = numbers.Where(x => x > 1); '1
IEnumerable<int> r2 = r1.Select(x => x + 1); '2
int result = r2.Sum(); '3
In this example, the execution of lines ‘1 and ‘2 is delayed until line ‘3. These LINQ statements are not evaluated until it’s necessary to generate the result. This occurs when calling methods like ToList(), Sum(), or similar operations that consolidate the data.
If you want to keep this lazy evaluation feature, then using IEnumerable<T> as the return type is suitable. If not, you should choose IReadOnlyList<T> for its additional functionalities.
IEnumerable<T> with an ORM
Note that lazy evaluation also leads to IEnumerable<T> being a leaky abstraction in some scenarios. Look at this code for example:
public IEnumerable<EmployeeDto> GetAll()
{
IEnumerable<Employee> employees = _repository.GetAll("vivasoftemployee.com");
IEnumerable<EmployeeDto> dtos = employees.Select(MapDto);
return dtos.ToList(); // Only method like this trigger query execution
}
The code in the first line (and even in the second one) is only executed when we call ToList<T>. If by that time the DbContext/ISession is already disposed of, we get an exception.
This situation is an example of a leaky abstraction. It’s considered leaky because EF Core necessitates knowing if the underlying database connection is open when the IEnumerable<T> is evaluated.
In simpler terms, EF Core adds an extra, hidden requirement. This requirement is not obvious because the IEnumerable<T> interface doesn’t indicate that you need to monitor the database connection, yet EF Core expects this.
It’s important to note that this issue with the IEnumerable<T> interface is less significant compared to IQueryable<T>. This is because, in most web applications, having an active and non-disposed DbContext (or ISession in NHibernate) throughout the duration of a business operation is a typical scenario. The DbContext is generally only disposed at the end of the operation.
However, the fact remains that lazy evaluation of database operations does not adhere to the Liskov Substitution Principle (LSP) for the IEnumerable<T> interface, leading to a leaky abstraction. If you don’t need lazy evaluation, it’s generally better to use IReadOnlyList<T> instead.
IEnumerable<T> without an ORM
Implementations of IEnumerable<T> can act as leaky abstractions even in scenarios where an ORM is not involved.
For instance, BlockingCollection implements IEnumerable<T> in a way that the MoveNext() method blocks the calling thread. This block continues until another thread adds an element to the collection:
public void Test()
{
BlockingCollection<int> collection = new BlockingCollection<int>();
IEnumerator<int> enumerator = collection.GetConsumingEnumerable().GetEnumerator();
bool moveNext = enumerator.MoveNext(); // The calling thread is blocked
}
And there are countless implementations of IEnumerable<T> that exhibit similar behavior. For example, you could write an infinite random number generator that implements IEnumerable<int>, like this:
private IEnumerable<int> Test2()
{
Random random = new Random();
while (true)
{
yield return random.Next();
}
}
If you use ToList() on such an implementation, the program will end up in an infinite loop.
Technically, these implementations aren’t considered leaky abstractions because the IEnumerable<T> interface doesn’t guarantee that a collection is final (meaning it doesn’t have a Count property).
However, in practice, most programmers expect certain behaviors from IEnumerable<T>. They usually anticipate that collections are finite and that calls to MoveNext() won’t block. This forms an implicit contract that many programmers rely on. Some implementations of IEnumerable<T> break this contract and thus can be seen as leaky abstractions.
IEnumerable<T> in library development
When developing enterprise applications, it’s usually best to return the most specific type possible, like IReadOnlyList<T>. However, the approach differs in library development.
When you’re creating a library for public use, you’ll want to limit its public API as much as possible. This limitation includes reducing the number of public methods and the specificity of the types these methods return. Essentially, you want to promise as little as possible to allow flexibility in future updates.
In this context, returning IEnumerable<T> instead of IReadOnlyList<T> is preferable. It lets you change the internal implementation—for example, switching from List<T> to LinkedList<T> without affecting those who use your library, thus maintaining backward compatibility.
This principle doesn’t usually apply to regular enterprise application development. In such cases, since your team is the primary user of your code, maintaining backward compatibility is less of a concern. You have more freedom to refactor your code as necessary if the API changes.
This approach aligns with the Open-Closed Principle, which advocates for designing software entities that are open for extension but closed for modification.
Final Thoughts
Here’s a summary of the guidelines for handling collection types in .NET:
Guideline Overview
Use IEnumerable<T> for arguments to maximize flexibility, as it is the most generic type available.
Use IReadOnlyList<T> for return values to provide more specific functionality, such as indexing and counting, which are often necessary for consuming code.
Concerns with IQueryable<T>
IQueryable<T> is considered a leaky abstraction because it demands knowledge of which LINQ expressions the underlying ORM can process. This requirement can expose implementation details and reduce the portability of the code.
Issues with IList<T> and Array
IQueryable<T> is considered a leaky abstraction because it demands knowledge of which LINQ expressions the underlying ORM can process. This requirement can expose implementation details and reduce the portability of the code.
Caveats with IEnumerable<T>
While IEnumerable<T> is recommended for arguments, it’s important to remember that some implementations of IEnumerable<T> can also act as leaky abstractions.
For instance, operations on collections like BlockingCollection may block, which isn’t evident just from using the IEnumerable<T> interface.
This approach aligns with best practices for ensuring that your application’s APIs are both robust and flexible, while also being mindful of potential pitfalls in .NET collection management.
Optimize your .NET methods by choosing the right collection type. If you need expert guidance on your .NET methods, hire dedicated .NET developers from Vivasoft.
Our team can help you select and implement the best collection types, boosting performance and maintainability.
Contact us today to your .NET development!














